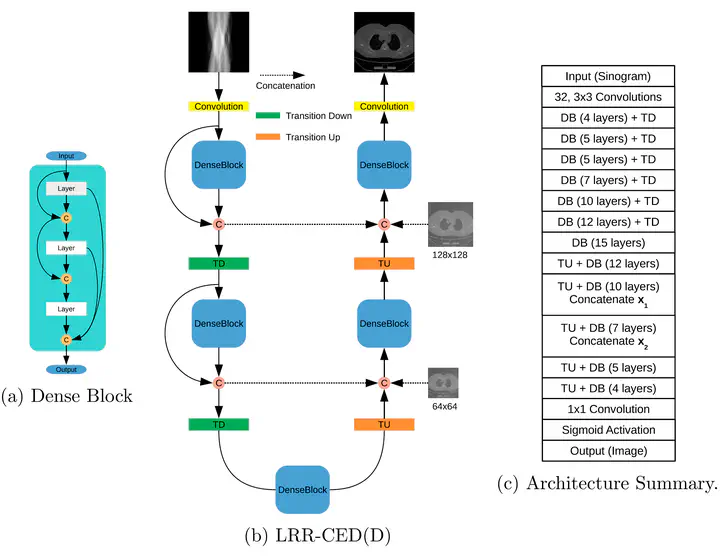
LRR-CED low-resolution reconstruction-aware convolutional encoder
Objective Sparse-view computed tomography (CT) reconstruction has been at the forefront of research in medical imaging. Reducing the total x-ray radiation dose to the patient while preserving the reconstruction accuracy is a big challenge. The sparse-view approach is based on reducing the number of rotation angles, which leads to poor quality reconstructed images as it introduces several artifacts. These artifacts are more clearly visible in traditional reconstruction methods like the filtered-backprojection (FBP) algorithm.
Approach Over the years, several model-based iterative and more recently deep learning-based methods have been proposed to improve sparse-view CT reconstruction. Many deep learning-based methods improve FBP-reconstructed images as a post-processing step. In this work, we propose a direct deep learning-based reconstruction that exploits the information from low-dimensional scout images, to learn the projection-to-image mapping. This is done by concatenating FBP scout images at multiple resolutions in the decoder part of a convolutional encoder decoder (CED).
Main results This approach is investigated on two different networks, based on Dense Blocks and U-Net to show that a direct mapping can be learned from a sinogram to an image. The results are compared to two post-processing deep learning methods (FBP-ConvNet and DD-Net) and an iterative method that uses a total variation (TV) regularization.
Significance This work presents a novel method that uses information from both sinogram and low-resolution scout images for sparse-view CT image reconstruction. We also generalize this idea by demonstrating results with two different neural networks. This work is in the direction of exploring deep learning across the various stages of the image reconstruction pipeline involving data correction, domain transfer and image improvement.